クローラーとインデックスの仕組みを図解入りで解説します。
検索エンジン領域で活動するなら検索エンジン領域の構造や成り立ちを基礎的な部分だけでも良いから理解しておいた方が良いと思ったので、自分の備忘録的にまとめてみました。
言葉は知ってたけど意味合いは??と思ってた人の参考になれば幸いです。
クローラーとインデックスの仕組み
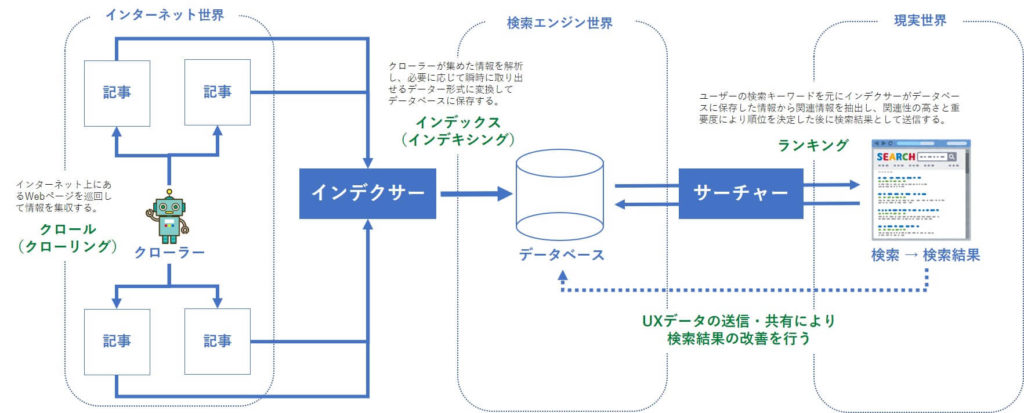
インターネット世界にクローラーと呼ばれるロボットがが回遊しており、様々な記事コンテンツを発見します。
発見したコンテンツをインデクサを経由してインデックスさせ、インデックスされた記事コンテンツ=検索エンジンに登録されたコンテンツとなるので、登録された記事コンテンツが検索結果に反映されます。
クローラーとは?
検索エンジンが検索結果を表示するためのインターネット世界に存在するwebページ(文字・画像・動画、など)を発見するロボット(自動巡回プログラム)のことです。
クローラーに発見されなければ検索エンジンに登録(インデックス)されないので、いかにしてクローラーを呼び込むか?クローラーの巡回頻度を高めるか?がサイト運営者の課題の1つと言えます。
クローラーの種類
| クローラー | 検索エンジン |
| Googlebot | |
| Yahoo Slurp | 日本以外のYahoo |
| Baiduspider | Baidu |
| bingbot | Bing |
| YandexBot | YANDEX |
| Mail.RU_Bot | Mail.ru |
| Yetibot | NAVER |
| AppleBot | SiriやSpotLight |
日本の検索エンジンシェアはGoogleがほぼ(Yahooの検索エンジンもGoogleのものを使用している)、実質9割以上はGoogleとなるので、日本国内でのクローラーはGooglebotだけ意識しておけばほぼ問題ありません。
| クローラー | SEOツール |
| MJ12bot | Majestic |
| SemrushBot | Semrush |
| AhrefsBot | Ahrefs |
| DotBot | OpenSiteExplorer |
上記は「SEOツールによるクローラー」という特殊な種類です。
該当ツール利用者以外には関係の無いお話ですが「こんな種類もあるんだよ」という補足的な意味合いで一部まとめてみました。
クロール(クローリング)
クローラーが回遊することをクロール(クローリング)と呼びます。
クローラーの周回頻度を高める(クローラビリティを高める)ことを意識してサイト運営する方も多いので、クローラーのことを総称して「クロール」という名称で理解している方もいるかと思います。
[クローラーが読み込む情報]
- HTML
- CSS
- JavaScript
- 画像(GIF/JPEG/PNG/WebP/SVG)
- 動画(MP4/WebMなど)
- オフィス文書(Word/Excel/PowerPoint)
【補足解説】クローラーが情報を解析する作業(パーシング)
(例1)
<title>タラバガニ - Wikipedia</title>このように記載されていれば「titleタグに囲まれている『タラバガニ – Wikipedia』という部分はそのページのtitle部分であると解析処理を行う。
(例2)
<a href=”https://ja.wikipedia.org/wiki/タラバガニ”>タラバガニ</a><br />
このように記載されていれば「タラバガニという文言に対してリンク先があるぞ」と判断する。
(例3)
<img src=”https://upload.wikimedia.org/KingCrab-reverse.JPG” alt=”タラバガニ” />このように記載されていれば「https://upload.wikimedia.org/KingCrab-reverse.JPG」は画像で、この画像は「タラバガニ」というテキストと等価であると解析処理をする
クローラビリティを高める
クローラーは人間のように見た目でリンクを判断するのではなくHTMLソース上のタグを読んで判断します。また、HTMLの中にあるリンクを発見しては辿っていくことで次々とWebページを巡回して情報を取得していきます。
クローラビリティを高めるなら以下の取り組みが対策の基本軸となります。
- 適切なタグの使用
- 内部リンク構造を考えたサイト構造の設計
- 外部リンクの増加
- 記事を更新してクローラーに見つけてもらう機会を増やす
具体的な作業項目としては以下をご参考ください。
[クロール周期を促進させる方法]
- URL検査
- 内部リンク・外部リンク(相互リンク)
- URL正規化(無駄ページの調整・統一)
- PING送信
- RSSフィード
- PubSubHubbub
- リンク切れを無くす
- サーバーの応答を改善する(表示スピードの改善)
- リンクのないページを排除(リンクがまったく存在しないページは、クローラビリティを低下させる要因)
- トップページからの必要クリック数を抑える(どのページに対してもトップページから3クリック以内で到達できることが理想)
- トップページから主要ページへ直接リンク
- ヒントを提示する
- XMLサイトマップ
- robots.txtで指示を出す
- rel=”nofollow”属性
- meta name=“robots” content=“nofollow”
クローラビリティー改善に関しては以下の記事もご参考になさってください。
【クローラビリティ関連記事】
クローラーの役割はWebページの収集のみ
クローラーが収集したWebページを解析するのはインデクサというプログラムの役割になります。
インデクサとインデックスに関しては続けて下記をご参考になさってください。
インデックスとは?
クローラーがインターネット上から発見したページを検索エンジンのデータベースに「登録」することを指します。
インデクサの役割
クローラーが集めた情報をインデクサというプログラムが解析し、必要に応じて瞬時に取り出せるデーター形式に変換してデータベースに保存します。
[インデクサの活動]
- ページ解析やリンク解析を行い、検索アルゴリズムがスコアリング時に使用しやすいよう、それらの状態を指標化する
- ページ解析を行って、HTMLソース内の検索に必要の無い(スクリプト記述部分など)部分を明かにする
- 形態素解析などによって文章を単語に切り分け、ページ内の個々の単語が文書内のどの位置に存在するのか、その位置情報を明かにする
インデクサはドキュメントの解析の結果をもとにして、情報ブロック(単語・HTML要素など)ごとにその位置や性質・重要性をデータ化。
そして、データを中間コード化した「転置ファイル」のかたちにしてまとめてインデックスに格納します。
[転置ファイルの例]
- 文書ファイル
形態素解析などで単語に切り分けられたドキュメントに対して、その切り分けた文字列ごとにユニークな識別コードを施したファイル。 - 転置リスト
「文書ファイル」に施した識別コードをドキュメント内の記述順に並べた上で個々の文字列に対応するシステム全体で決められている単語の識別コードを並記したリスト。単語の識別コードだけでなく、HTML要素の種類やそのWebページのリンクポピュラリティの値など、あらゆる属性を与える場合がある。 - 辞書ファイル
検索アルゴリズムで扱う単語ごとに、該当する「転置リスト」の所在と、その中での位置情報・性質(HTML要素の種類やリンクポピュラリティの値など)をコード化してまとめたもの。
なお、ページがインデックスされているかどうか?はサーチコンソールやコマンド検索によって確認ができます。詳しくは以下の記事にある手順をご参照ください。
ランキングは更に次の行程になる
データベースに登録した情報を元に、ユーザーが入力したキーワードに対して「クエリーサーバーから受け取った検索結果」をランキング表示します。(ランキングの機能はここで発動します。)
データベースへの登録にあたり、仮に同じ内容でも機械側(検索エンジン側)が理解しやすい記述で書かれたページの方がSEO的には評価されるようになります。
インデックスの特徴
公式の見解というよりも、公式見解を踏まえた上での自分の体感値込みでの見解だと思ってください。
更新頻度が高いページに集まりやすい
頻繁に更新されるページは頻繁にクローリングされやすい傾向にあります。
数秒に1回更新されるようなページは1日に何回もクローリングされるが、放置されているページであればクローラーはほとんど来なくなります。
生き物みたいだね。
クローラーの周回頻度が高い=重要度が高い、と認識されやすい
検索エンジンが重要であると判断したページは、クローリングされる頻度が上がりやすい。
また、更新頻度が高くなくても重要度の高いページであれば相対的にクローリング頻度はあがる傾向にあります。
インデクサビリティが高い方がインデックス時に正確に評価されやすい
[インデクサビリティ]
検索エンジンのロボットがページの内容を正確にインデックスできるようにするために画像や音声、動画に対して適切な代替コンテンツを用意したり、ページ内の各要素の構造を適切にマークアップすることを指します。
検索エンジンのロボットはページ中の文字情報とリンク情報を中心に情報を取得します。
つまり、文字情報とリンク情報しか理解しないブラウザ(テキストブラウザのような)で見た場合にもきちんと利用可能かつ理解可能なサイトにすることが、クローラビリティおよびインデクサビリティの確保につながります。
なお、画像よりもテキストの方がインデクサビリティが高く、また、HTMLは論理的構造に則ったマークアップ(ページ内容により見出し・段落・リスト・定義リストなど使い分けることを意味します。)をすると検索エンジンが理解しやすくなります。
クロールバジェット
Googleにもクローラー自身のリソース上限(クロールバジェットと呼ばれる)に限りがあるので「どのURLでも同じ頻度で」というわけにはいかない。
ただし、巡回速度の問題が顕著になるのは数千ページ以上の巨大なサイトの場合なので、個人サイト規模なら基本的には気にしないでOKであることが多い。
Q: サイトの表示速度はクロール バジェットに影響しますか?エラーについてはどうですか?
Googlebot のクロール バジェットとは?
A: サイトの表示速度を上げると、ユーザーの利便性が向上するだけでなく、クロール速度も上がります。Googlebotは、速度に優れたサイトはサーバーが健全な状態であることを表すものと見なすので、同じ接続の数でより多くのコンテンツの取得が可能になります。一方、5xx エラーや接続タイムアウトが多い場合はサーバーの状態に問題があると見なされ、クロールが遅くなります。
クロールの速度に影響する指標
- ページに人気がある
- ページの表示速度が速い
- 重複コンテンツが少ない
- サーバーエラーが少ない
クローラビリティ改善を検討する際は上記項目を念頭にコンテンツ制作を行うと良い傾向にあります。
その他の特徴・傾向
- インデックスされたページの数はSEOに関係ない
- 価値の低いページを大量に作り全てインデックスさせたとしても
その数をもってサイトの評価が上がることはない - SEOで大事なのは「質の高いページ」がたくさんありインデックスされていること
とりあえず数を作れば良いわけではありません。
読み手に価値を提供できる質の高い記事を作成することが第一であり、インデックスされるページの数は結果論でしかない、ということです。
参考:低品質ページを大量生産しても検索エンジンの評価は上がらない、高品質コンテンツだけを作る | 海外SEO情報ブログ
参考:Does a site rank better if it has a lot of indexed pages?? YouTube
Googleがページをクロール対象外と判断するケース
- robots.txt でブロックされたページはクロールされませんが、別のページにリンクされている場合には、インデックスに登録される可能性があります。(Google は、ページへのリンクをもとにページの内容を推測し、コンテンツを解析せずにそのページをインデックス登録することがあります)
- Google では、匿名ユーザーがアクセスできないページはクロールできません。したがって、ログインなどの認証によって保護されたページはクロールされません。
- すでにクロール済みで、別のページの重複バージョンと見なされるページに対しては、クロールの頻度が少なくなります。
まとめ
各種改めて調べた上で今後のメディア運営にどう活かすか?を考えた時に「良い記事コンテンツ作ろうぜ!」という答えに着地しました。笑
新しく作成した記事・リライトして改善した記事を検索エンジンに認識させることは検索エンジン領域で活動するうえで欠かせない作業です。
クローラビリティを改善しインデックスされやすく、且つ、読み手に価値を感じてもらえるサイト作りを進めていきましょう。
クローラーの周回頻度を数字で確認したい方は以下の記事を参考にご確認ください。